
September 19, 2017 From rOpenSci (https://deploy-preview-121--ropensci.netlify.app/blog/2017/09/19/patentsview/). Except where otherwise noted, content on this site is licensed under the CC-BY license.
 Why care about patents?
Why care about patents?
1. Patents play a critical role in incentivizing innovation, without which we wouldn’t have much of the technology we rely on everyday
What does your iPhone, Google’s PageRank algorithm, and a butter substitute called Smart Balance all have in common?


…They all probably wouldn’t be here if not for patents. A patent provides its owner with the ability to make money off of something that they invented, without having to worry about someone else copying their technology. Think Apple would spend millions of dollars developing the iPhone if Samsung could just come along and rip it off? Probably not.
2. Patents offer a great opportunity for data analysis
There are two primary reasons for this:
- Patent data is public. In return for the exclusive right to profit off an invention, an individual/company has to publicly disclose the details of their invention to the rest of the world. Examples of those details include the patent’s title, abstract, technology classification, assigned organizations, etc.
- Patent data can answer questions that people care about. Companies (especially big ones like IBM and Google) have a vested interest in extracting insights from patents, and spend a lot of time/resources trying figure out how to best manage their intellectual property (IP) rights. They’re plagued by questions like “who should I sell my underperforming patents to,” “which technology areas are open to new innovations,” “what’s going to be the next big thing in the world of buttery spreads,” etc. Patents offer a way to provide data-driven answers to these questions.
Combined, these two things make patents a prime target for data analysis. However, until recently it was hard to get at the data inside these documents. One had to either collect it manually using the official United States Patent and Trademark Office (USPTO) search engine, or figure out a way to download, parse, and model huge XML data dumps. Enter PatentsView.
PatentsView and the patentsview package
PatentsView is one of USPTO’s new initiatives intended to increase the usability and value of patent data. One feature of this project is a publicly accessible API that makes it easy to programmatically interact with the data. A few of the reasons why I like the API (and PatentsView more generally):
- The API is free (no credential required) and currently doesn’t impose rate limits/bandwidth throttling.
- The project offers bulk downloads of patent data on their website (in a flat file format), for those who want to be closest to the data.
- Both the API and the bulk download data contain disambiguated entities such as inventors, assignees, organizations, etc. In other words, the API will tell you whether it thinks that John Smith on patent X is the same person as John Smith on patent Y. 1
The patentsview R package is a wrapper around the PatentsView API. It
contains a function that acts as a client to the API (search_pv()) as
well as several supporting functions. Full documentation of the package
can be found on its
website.
Installation
You can install the stable version of patentsview from CRAN:
install.packages("patentsview")
Or get the development version from GitHub:
if (!require(devtools)) install.packages("devtools")
devtools::install_github("ropensci/patentsview")
Getting started
The package has one main function, search_pv(), that makes it easy to
send requests to the API. There are two parameters to search_pv() that
you’re going to want to think about just about every time you call it -
query and fields. You tell the API how you want to filter the patent
data with query, and which fields you want to retrieve with
fields. 2
query
Your query has to use the PatentsView query
language, which is
a JSON-based syntax that is similar to the one used by Lucene. You can
write the query directly and pass it as a string to search_pv():
library(patentsview)
qry_1 <- '{"_gt":{"patent_year":2007}}'
search_pv(query = qry_1, fields = NULL) # This will retrieve a default set of fields
#> $data
#> #### A list with a single data frame on the patent data level:
#>
#> List of 1
#> $ patents:'data.frame': 25 obs. of 3 variables:
#> ..$ patent_id : chr [1:25] "7313829" ...
#> ..$ patent_number: chr [1:25] "7313829" ...
#> ..$ patent_title : chr [1:25] "Sealing device for body suit and sealin"..
#>
#> $query_results
#> #### Distinct entity counts across all downloadable pages of output:
#>
#> total_patent_count = 100,000
…Or you can use the domain specific language (DSL) provided in the
patentsview package to help you write the query:
qry_2 <- qry_funs$gt(patent_year = 2007) # All DSL functions are in the qry_funs list
qry_2 # qry_2 is the same as qry_1
#> {"_gt":{"patent_year":2007}}
search_pv(query = qry_2)
#> $data
#> #### A list with a single data frame on the patent data level:
#>
#> List of 1
#> $ patents:'data.frame': 25 obs. of 3 variables:
#> ..$ patent_id : chr [1:25] "7313829" ...
#> ..$ patent_number: chr [1:25] "7313829" ...
#> ..$ patent_title : chr [1:25] "Sealing device for body suit and sealin"..
#>
#> $query_results
#> #### Distinct entity counts across all downloadable pages of output:
#>
#> total_patent_count = 100,000
qry_1 and qry_2 will result in the same HTTP call to the API. Both
queries search for patents in USPTO that were published after 2007.
There are three gotchas to look out for when writing a query:
- Field is queryable. The API has 7 endpoints (the default
endpoint is “patents”), and each endpoint has its own set of fields
that you can filter on. The fields that you can filter on are not
necessarily the same as the ones that you can retrieve. In other
words, the fields that you can include in
query(e.g.,patent_year) are not necessarily the same as those that you can include infields. To see which fields you can query on, look in thefieldsdfdata frame (View(patentsview::fieldsdf)) for fields that have a “y” indicator in theircan_querycolumn for your given endpoint. - Correct data type for field. If you’re filtering on a field in
your query, you have to make sure that the value you are filtering
on is consistent with the field’s data type. For example,
patent_yearhas type “integer,” so if you pass 2007 as a string then you’re going to get an error (patent_year = 2007is good,patent_year = "2007"is no good). You can find a field’s data type in thefieldsdfdata frame. - Comparison function works with field’s data type. The comparison
function(s) that you use (e.g., the greater-than function shown
above,
qry_funs$gt()) must be consistent with the field’s data type. For example, you can’t use the “contains” function on fields of type “integer” (qry_funs$contains(patent_year = 2007)will throw an error). See?qry_funsfor more details.
In short, use the fieldsdf data frame when you write a query and you
should be fine. Check out the writing queries
vignette
for more details.
fields
Up until now we have been using the default value for fields. This
results in the API giving us some small set of default fields. Let’s see
about retrieving some more fields:
search_pv(
query = qry_funs$gt(patent_year = 2007),
fields = c("patent_abstract", "patent_average_processing_time",
"inventor_first_name", "inventor_total_num_patents")
)
#> $data
#> #### A list with a single data frame (with list column(s) inside) on the patent data level:
#>
#> List of 1
#> $ patents:'data.frame': 25 obs. of 3 variables:
#> ..$ patent_abstract : chr [1:25] "A sealing device for a"..
#> ..$ patent_average_processing_time: chr [1:25] "1324" ...
#> ..$ inventors :List of 25
#>
#> $query_results
#> #### Distinct entity counts across all downloadable pages of output:
#>
#> total_patent_count = 100,000
The fields that you can retrieve depends on the endpoint that you are
hitting. We’ve been using the “patents” endpoint thus far, so all of
these are retrievable:
fieldsdf[fieldsdf$endpoint == "patents", "field"]. You can also use
get_fields() to list the retrievable fields for a given endpoint:
search_pv(
query = qry_funs$gt(patent_year = 2007),
fields = get_fields(endpoint = "patents", groups = c("patents", "inventors"))
)
#> $data
#> #### A list with a single data frame (with list column(s) inside) on the patent data level:
#>
#> List of 1
#> $ patents:'data.frame': 25 obs. of 31 variables:
#> ..$ patent_abstract : chr [1:25] "A sealing devi"..
#> ..$ patent_average_processing_time : chr [1:25] "1324" ...
#> ..$ patent_date : chr [1:25] "2008-01-01" ...
#> ..$ patent_firstnamed_assignee_city : chr [1:25] "Cambridge" ...
#> ..$ patent_firstnamed_assignee_country : chr [1:25] "US" ...
#> ..$ patent_firstnamed_assignee_id : chr [1:25] "b9fc6599e3d60c"..
#> ..$ patent_firstnamed_assignee_latitude : chr [1:25] "42.3736" ...
#> ..$ patent_firstnamed_assignee_location_id: chr [1:25] "42.3736158|-71"..
#> ..$ patent_firstnamed_assignee_longitude : chr [1:25] "-71.1097" ...
#> ..$ patent_firstnamed_assignee_state : chr [1:25] "MA" ...
#> ..$ patent_firstnamed_inventor_city : chr [1:25] "Lucca" ...
#> ..$ patent_firstnamed_inventor_country : chr [1:25] "IT" ...
#> ..$ patent_firstnamed_inventor_id : chr [1:25] "6416028-3" ...
#> ..$ patent_firstnamed_inventor_latitude : chr [1:25] "43.8376" ...
#> ..$ patent_firstnamed_inventor_location_id: chr [1:25] "43.8376211|10."..
#> ..$ patent_firstnamed_inventor_longitude : chr [1:25] "10.4951" ...
#> ..$ patent_firstnamed_inventor_state : chr [1:25] "Tuscany" ...
#> ..$ patent_id : chr [1:25] "7313829" ...
#> ..$ patent_kind : chr [1:25] "B1" ...
#> ..$ patent_number : chr [1:25] "7313829" ...
#> ..$ patent_num_cited_by_us_patents : chr [1:25] "5" ...
#> ..$ patent_num_claims : chr [1:25] "25" ...
#> ..$ patent_num_combined_citations : chr [1:25] "35" ...
#> ..$ patent_num_foreign_citations : chr [1:25] "0" ...
#> ..$ patent_num_us_application_citations : chr [1:25] "0" ...
#> ..$ patent_num_us_patent_citations : chr [1:25] "35" ...
#> ..$ patent_processing_time : chr [1:25] "792" ...
#> ..$ patent_title : chr [1:25] "Sealing device"..
#> ..$ patent_type : chr [1:25] "utility" ...
#> ..$ patent_year : chr [1:25] "2008" ...
#> ..$ inventors :List of 25
#>
#> $query_results
#> #### Distinct entity counts across all downloadable pages of output:
#>
#> total_patent_count = 100,000
Example
Let’s look at a quick example of pulling and analyzing patent data. We’ll look at patents from the last ten years that are classified below the H04L63/00 CPC code. Patents in this area relate to “network architectures or network communication protocols for separating internal from external traffic.” 3 CPC codes offer a quick and dirty way to find patents of interest, though getting a sense of their hierarchy can be tricky.
- Download the data
library(patentsview)
# Write a query:
query <- with_qfuns( # with_qfuns is basically just: with(qry_funs, ...)
and(
begins(cpc_subgroup_id = 'H04L63/02'),
gte(patent_year = 2007)
)
)
# Create a list of fields:
fields <- c(
c("patent_number", "patent_year"),
get_fields(endpoint = "patents", groups = c("assignees", "cpcs"))
)
# Send HTTP request to API's server:
pv_res <- search_pv(query = query, fields = fields, all_pages = TRUE)
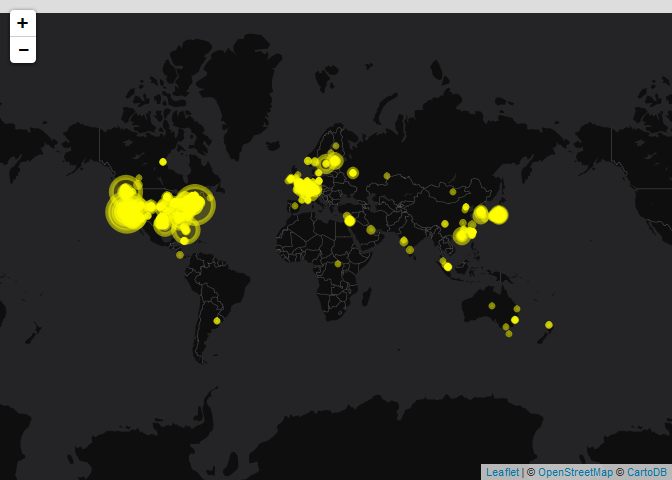
- See where the patents are coming from (geographically)
library(leaflet)
library(htmltools)
library(dplyr)
library(tidyr)
data <-
pv_res$data$patents %>%
unnest(assignees) %>%
select(assignee_id, assignee_organization, patent_number,
assignee_longitude, assignee_latitude) %>%
group_by_at(vars(-matches("pat"))) %>%
mutate(num_pats = n()) %>%
ungroup() %>%
select(-patent_number) %>%
distinct() %>%
mutate(popup = paste0("<font color='Black'>",
htmlEscape(assignee_organization), "<br><br>Patents:",
num_pats, "</font>")) %>%
mutate_at(vars(matches("_l")), as.numeric) %>%
filter(!is.na(assignee_id))
leaflet(data) %>%
addProviderTiles(providers$CartoDB.DarkMatterNoLabels) %>%
addCircleMarkers(lng = ~assignee_longitude, lat = ~assignee_latitude,
popup = ~popup, ~sqrt(num_pats), color = "yellow")
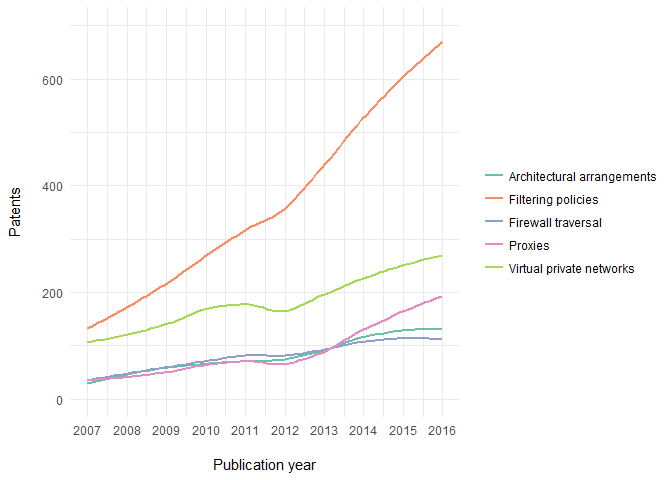
- Plot the growth of the field’s topics over time
library(ggplot2)
library(RColorBrewer)
data <-
pv_res$data$patents %>%
unnest(cpcs) %>%
filter(cpc_subgroup_id != "H04L63/02") %>% # remove patents categorized into only top-level category of H04L63/02
mutate(
title = case_when(
grepl("filtering", .$cpc_subgroup_title, ignore.case = T) ~
"Filtering policies",
.$cpc_subgroup_id %in% c("H04L63/0209", "H04L63/0218") ~
"Architectural arrangements",
grepl("Firewall traversal", .$cpc_subgroup_title, ignore.case = T) ~
"Firewall traversal",
TRUE ~
.$cpc_subgroup_title
)
) %>%
mutate(title = gsub(".*(?=-)-", "", title, perl = TRUE)) %>%
group_by(title, patent_year) %>%
count() %>%
ungroup() %>%
mutate(patent_year = as.numeric(patent_year))
ggplot(data = data) +
geom_smooth(aes(x = patent_year, y = n, colour = title), se = FALSE) +
scale_x_continuous("\nPublication year", limits = c(2007, 2016),
breaks = 2007:2016) +
scale_y_continuous("Patents\n", limits = c(0, 700)) +
scale_colour_manual("", values = brewer.pal(5, "Set2")) +
theme_bw() + # theme inspired by https://hrbrmstr.github.io/hrbrthemes/
theme(panel.border = element_blank(), axis.ticks = element_blank())
Learning more
For analysis examples that go into a little more depth, check out the
data applications
vignettes
on the package’s website. If you’re just interested in search_pv(),
there are
examples
on the site for that as well. To contribute to the package or report an
issue, check out the issues page on
GitHub.
Acknowledgments
I’d like to thank the package’s two reviewers, Paul Oldham and Verena Haunschmid, for taking the time to review the package and providing helpful feedback. I’d also like to thank Maëlle Salmon for shepherding the package along the rOpenSci review process, as well Scott Chamberlain and Stefanie Butland for their miscellaneous help.
-
This is both good and bad, as there are errors in the disambiguation. The algorithm that is responsible for the disambiguation was created by the winner of the PatentsView Inventor Disambiguation Technical Workshop. ↩︎
-
These two parameters end up getting translated into a MySQL query by the API’s server, which then gets sent to a back-end database.
queryandfieldsare used to create the query’sWHEREandSELECTclauses, respectively. ↩︎ -
There is a slightly more in-depth definition that says that these are patents “related to the (logical) separation of traffic/(sub-) networks to achieve protection.” ↩︎
