
October 9, 2019 From rOpenSci (https://deploy-preview-121--ropensci.netlify.app/technotes/2019/10/09/cran-checks-api-update/). Except where otherwise noted, content on this site is licensed under the CC-BY license.
If you have an R package on CRAN, you probably know about CRAN checks. Each package on CRAN, that is not archived on CRAN1, has a checks page, like this one for ropenaq:
https://cloud.r-project.org/web/checks/check_results_ropenaq.html
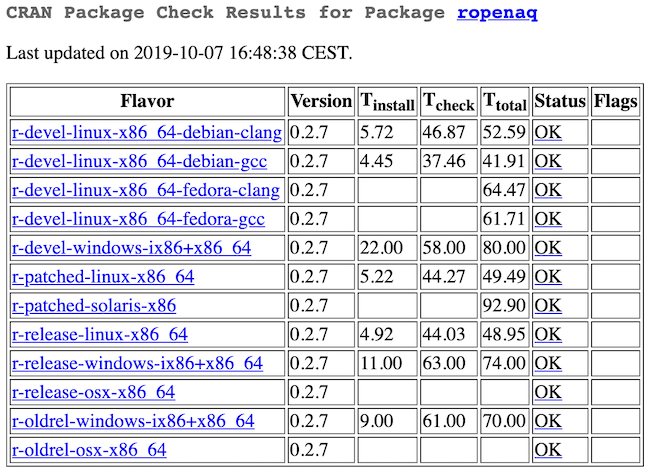
The table above is results of running R CMD CHECK on the package on a combination of different operating systems, R versions and compilers. CRAN maintainers presumably use these as a basis for getting in touch with maintainers when these checks are failing.
It’s great that packages are being tested in a variety of scenarios to make sure each package will work for as many users as possible.
The only drawback to CRAN checks is that they are not available in a machine readable way. When information is made available as machine readable many additional things become possible.
 CRAN Checks API
CRAN Checks API
For a recent overview of the API, check out the Overview of the CRAN checks API blog post on the R-Hub blog.
To make CRAN check data available in a machine readable we built out the CRAN checks API. Over the two years since it began, the API has gotten some tweaks and fixes, some of which are very recent.
When the API first came out the only routes were:
/heartbeat/docs/pkgs/pkgs/:pkg_name:
Now the routes are:
/heartbeat/docs/pkgs/pkgs/:pkg_name:/pkgs/:pkg_name:/history/history/:date/maintainers/maintainers/✉️/badges/:type/:package/badges/flavor/:flavor/:package
The big new additions since the beginning are maintainers, badges, and history; I’ll briefly talk about each.
Maintainers
The maintainers route gives you access to the data on the summary pages by package maintainer https://cloud.r-project.org/web/checks/check_summary_by_maintainer.html. /maintainers gives all maintainers data, while with /maintainers/✉️ you can get data for a specific maintainer (by their email address). Note that with /maintainers/✉️ at this time you need to use the format CRAN uses for emails to get a match in the API; e.g., with the package ropenaq, the maintainer’s (Maëlle Salmon) email is maelle.salmon@yahoo.se, but it needs to be formatted like /maintainers/maelle.salmon_at_yahoo.se in the API. I will at some point make it so that you can just use the actual email address in the route.
The data returned for the /maintainers API routes is not the detailed data you get on the /pkgs routes. There’s two main data fields.
The table slot has an array of hashes, one for each package, with a summary of how many checks were ok, note, warn, and error.
The packages slot has an array of hahes, one for each package, but includes the URL for the CRAN checks page, and similar to the table slot, has a summary of the number of checks in each category.
Badges






Badges routes are by far the most widely used routes on this API, with ~900 R packages using a cran checks badge. Within the /badges/:type/:package route, you can get a badge for either /badges/summary/:package or /badges/worst/:package, where the former gives you a badge as Not OK (red) or OK (green), and the latter gives the worst check result (error, warn, note, and ok; each w/ a different color).
The /badges/flavor/:flavor/:package route allows you to get a badge for a specific “flavor”, that is, an operating system OR an R version. For example, /badges/flavor/osx/ggplot2 or /badges/flavor/release/ggplot2.
If you request a badges route with an uknown flavor or package you get an gray unknown badge (see above).
To use a CRAN checks badge, simply copy/paste the below text into your README, changing the package name to your own, and selecting the type of badge you want:
[](https://cran.r-project.org/web/checks/check_results_reshape.html)
or
[](https://cranchecks.info/pkgs/reshape)
The former links to the CRAN checks page, while the latter links to the API route for the package.
History
We’ve had the /pkgs/:pkg_name:/history route for quite a while now, but it’s been very slow to respond because the SQL database was in an ideal situation (we had no indexes; and a ton of data). It’s now fixed, and you can very quickly get up to the last 30 days of checks history. We prune out any data older than 30 days; all older day gets put in an Amazon S3 bucket to save disk space on the server and to make them available for the /history/:date route.
If you want more than 30 days in the past, we’ve got a new route /history/:date to get all historical data by day, across all packages. It has daily data back to December 2018. There’s a few days missing here and there as I was learning and making mistakes. To get the data, send a request like /history/2019-10-01, and you’ll get a 302 redirect to a temporary URL (expires in 15 min) for the gzipped JSON file. You can easily get these in R like:
x <- jsonlite::stream_in(curl::curl("https://cranchecks.info/history/2019-10-01"))
str(x)
#> 'data.frame': 15167 obs. of 6 variables:
#> $ package : chr "localIV" "di" "GAR" "MetABEL" ...
#> $ summary : chr "{\"any\":false,\"ok\":12,\"note\":0,\"warn\":0,\"error\":0,\"fail\":0}" "{\"any\":false,\"ok\":12,\"note\":0,\"warn\":0,\"error\":0,\"fail\":0}" "{\"any\":false,\"ok\":12,\"note\":0,\"warn\":0,\"error\":0,\"fail\":0}" "{\"any\":true,\"ok\":0,\"note\":12,\"warn\":0,\"error\":0,\"fail\":0}" ...
#> $ checks : chr "[{\"flavor\":\"r-devel-linux-x86_64-debian-clang\",\"version\":\"0.2.1\",\"tinstall\":2.21,\"tcheck\":40.68,\"t"| __truncated__ "[{\"flavor\":\"r-devel-linux-x86_64-debian-clang\",\"version\":\"1.1.4\",\"tinstall\":2.54,\"tcheck\":24.8,\"tt"| __truncated__ "[{\"flavor\":\"r-devel-linux-x86_64-debian-clang\",\"version\":\"1.1\",\"tinstall\":1.87,\"tcheck\":20.85,\"tto"| __truncated__ "[{\"flavor\":\"r-devel-linux-x86_64-debian-clang\",\"version\":\"0.2-0\",\"tinstall\":2.59,\"tcheck\":19.27,\"t"| __truncated__ ...
#> $ check_details: chr "null" "null" "null" "{\"version\":\"0.2-0\",\"check\":\"package dependencies\",\"result\":\"NOTE\",\"output\":\"Package suggested bu"| __truncated__ ...
#> $ date_updated : chr "2019-10-01 15:02:40 UTC" "2019-10-01 15:02:40 UTC" "2019-10-01 15:02:40 UTC" "2019-10-01 15:02:40 UTC" ...
Note above that we use stream_in() because the JSON file is new-line delimited, or ND-JSON; each line in the file is valid JSON, but the entire file is not valid JSON. stream_in() pulls all that data into a nice data.frame, where you can parse as you like from there.
What else is possible now that we have an API?
One concrete idea I hope to pursue at some point:
- Notify package maintainers. Notifying them of exactly what would be up to the maintainer. Now that the API exists, we can much more easily build a notification system. For example, a maintainer could say they want to get an email whenever cran checks are failing more than 3 days in a row; or when cran checks details match a certain character string (e.g., segfault); or to ignore cran check results that are just failures due to temporary problems with a dependency package.
I’m sure there’s many other ideas I haven’t thought of 😸
What’s next?
- Notifications (see ropenscilabs/cchecksapi#13) may or may not happen - chime in there if you’re interested in helping with this.
- Add ability to ignore specific NOTEs for badges. It would be nice to ignore NOTEs that can be ignored so you aren’t getting a “something’s wrong” badge when nothing important is wrong (i.e., CRAN maintainers don’t contact the maintainer as it’s something rather trivial). See ropenscilabs/cchecksapi#29
- Have an idea or comment? open an issue
-
old versions of the package exist, but binaries are no longer built and checks are no longer performed ↩︎
